
문제
A trie (pronounced as "try") or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:
- Trie() Initializes the trie object.
- void insert(String word) Inserts the string word into the trie.
- boolean search(String word) Returns true if the string word is in the trie (i.e., was inserted before), and false otherwise.
- boolean startsWith(String prefix) Returns true if there is a previously inserted string word that has the prefix prefix, and false otherwise.
Example 1:
Input:
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
Output: [null, null, true, false, true, null, true]
Explanation Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // return True
trie.search("app"); // return False
trie.startsWith("app"); // return True
trie.insert("app");
trie.search("app"); // return True
문자열 데이터를 효율적으로 저장하고 검색하는 데 사용되는 Trie 자료구조를 작성하는 문제입니다.
풀이 1
이 문제를 푸는 시점에 Trie 자료구조를 잘 알지 못하였기 때문에 Set과 String에서 제공되는 startsWith을 활용하여 풀어 보았습니다.
1. insert -> set에 문자열을 넣어준다.
2. search -> set이 문자열을 가지고 있는지 확인한다.
3. startsWith -> set이 가지고있는 문자열을 순회하며startsWith(prefix)를 만족하는 String을 찾는다.
결과 1
class Trie {
Set<String> set;
public Trie() {
set = new HashSet<>();
}
public void insert(String word) {
set.add(word);
}
public boolean search(String word) {
return set.contains(word);
}
public boolean startsWith(String prefix) {
for (String str : set) {
if (str.startsWith(prefix)) {
return true;
}
}
return false;
}
}
문자열 검색에 최적화 되어있지 않은 방식으로 풀이하였을 때, 수행시간이 좋지 않게 나오는 결과를 볼 수 있습니다.
Trie 자료구조를 간단히 알아보고 구현해 보겠습니다.
Trie
- prefix tree, retrieval tree, radix tree 라고도 한다.
- 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조
- 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어 있는 자료구조
- 문자열의 길이가 N일 때, O(N) 시간 내에 문자열을 삽입, 검색, 삭제할 수 있습니다.
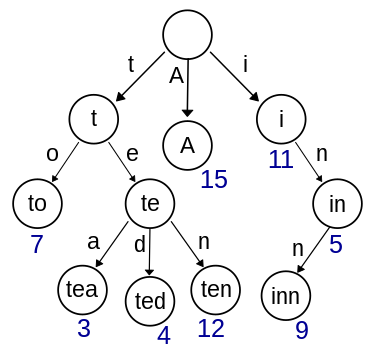
풀이2
1. Node는 알파벳 개수만큼 Node를 가질 수 있습니다.
insert
1. 입력받은 문자열의 0번째 문자부터 저장합니다.
2. 문자를 인덱스로 변환하여 (char - 'a') 새로운 노드를 추가합니다.
3. 문자가 끝난 경우 isEnd를 true로 지정합니다. isEnd가 true인 노드까지의 경로가 하나의 문자가 됩니다.
startsWith
1. 입력받은 문자열의 0번째 문자부터 검색합니다.
2. 문자를 인덱스로 변환하여 노드 배열에서 해당 인덱스를 가진 노드가 있는지 확인합니다.
3. null이라면 존재하지 않는 문자열이며, null이 아니라면 탐색을 계속 합니다.
4. 입력받은 문자열의 끝까지 검색했을 때, null을 만나지 않았다면 true를 반환합니다.
search
1. startWith과 동일한 방식으로 검색합니다. 이때, 문자열의 끝의 노드는 isEnd = true여야합니다.
결과2
class Trie {
Node root;
public Trie() {
root = new Node();
}
public void insert(String word) {
root.insert(word, 0);
}
public boolean search(String word) {
return root.search(word, 0);
}
public boolean startsWith(String prefix) {
return root.startsWith(prefix, 0);
}
class Node {
Node[] nodes;
boolean isEnd;
Node() {
nodes = new Node[26];
}
private void insert(String word, int idx) {
if (idx == word.length()) {
isEnd = true;
return;
}
int i = word.charAt(idx) - 'a';
if (nodes[i] == null) {
nodes[i] = new Node();
}
nodes[i].insert(word, idx + 1);
}
private boolean search(String word, int idx) {
if (idx >= word.length()) return false;
Node node = nodes[word.charAt(idx) - 'a'];
if (node == null) return false;
if (idx == word.length() - 1 && node.isEnd) return true;
return node.search(word, idx+1);
}
private boolean startsWith(String prefix, int idx) {
if (idx >= prefix.length()) return false;
Node node = nodes[prefix.charAt(idx) - 'a'];
if (node == null) return false;
if (idx == prefix.length() - 1) return true;
return node.startsWith(prefix, idx+1);
}
}
}
문자열 검색에 최적화된 자료구조 답게 수행시간이 훨씬 줄어든 결과를 볼수 있습니다.